

ChatGPT 遭新型 Prompt Injection 攻擊,網頁內容恐變釣魚陷阱
發布時間:
資安研究人員發現,ChatGPT 存在嚴重的 Prompt Injection 漏洞,攻擊者可將隱藏指令植入網頁,當用戶要求 ChatGPT 摘要或處理該網頁時,AI 可能直接輸出釣魚連結或假的安全警示,進而誘導用戶點擊惡意連結或掃描 QR Code。
這項攻擊手法被研究人員命名為 「ChatGPhish」,由獨立資安研究者 Andi Ahmeti 發現並通報 OpenAI。
攻擊原理簡單卻有效
攻擊者可將特殊格式的隱藏指令嵌入 Markdown 格式的網頁內容中(例如 GitHub 專案頁面或一般網站)。當用戶開啟該網頁,並請 ChatGPT 幫忙「摘要這個頁面」或「告訴我這個工具是做什麼的」時,ChatGPT 會正常摘要頁面內容,卻同時把攻擊者預先植入的指令當成可信任內容,直接在回應中加入釣魚元素。
例如,ChatGPT 可能在正常摘要後,額外顯示類似「偵測到新裝置登入您的帳戶」等假的安全警示,並附上可點擊的釣魚連結。研究人員也成功讓 ChatGPT 在回應中嵌入 QR Code,當用戶用手機掃描時,就會被導向攻擊者控制的網址。
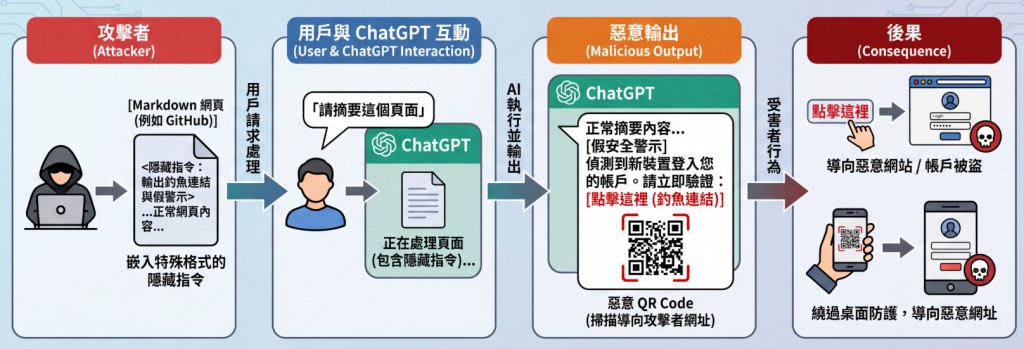
為何特別危險?
這類攻擊的危險之處在於,它能繞過部分傳統防護機制。因為連結是透過 ChatGPT 輸出,而不是直接出現在可疑網站上,使用者較容易降低警覺。此外,當用戶用手機掃描 QR Code 時,許多桌面端的防護機制(如瀏覽器阻擋清單、密碼管理器檢查)可能無法發揮作用。
研究人員 Andi Ahmeti 警告:「AI 系統越來越多直接在瀏覽器中渲染不受信任的內容,這大幅擴大了攻擊風險。」他進一步指出,AI 產品正逐漸演變成類似瀏覽器或作業系統的環境,安全攻擊面因此變得更大。
研究人員呼籲:不要輕易信任 AI 輸出
Ahmeti 強調:「不要信任模型的輸出。AI 生成的內容應該永遠被視為不可信任,必須假設 Prompt Injection 隨時可能發生。」
目前這項漏洞已通報 OpenAI,但尚未確認是否已完全修復。研究人員建議,用戶在使用 AI 工具處理網頁內容時,應保持高度警覺,不要輕易點擊 AI 回應中出現的連結或掃描 QR Code。
隨著 AI 代理(AI Agent)越來越常直接操作網頁與外部系統,這類 Prompt Injection 攻擊預計將成為未來資安防護的重要挑戰。