

Anthropic 發表自然語言自編碼器,揭示大型語言模型內部運作
分類: AI 新品報導 發布時間:
Anthropic 近日發表最新可解釋性(Interpretability)研究成果——Natural Language Autoencoders(NLA,自然語言自編碼器),成功將大型語言模型(如 Claude)的內部激活向量(activations)轉換為人類可直接閱讀的自然語言文字。這項技術被視為 AI 黑箱解釋領域的重要進展,有望大幅提升模型審核、安全性評估與透明度。
NLA 核心原理
傳統上,AI 模型的「思考」是以數值向量形式存在,難以直接理解。NLA 的方法是訓練模型讓它「解釋自己的思考」:
- Activation Verbalizer(AV):將模型的激活向量轉換成自然語言描述。
- Activation Reconstructor(AR):將描述文字反向重建回原始激活向量。
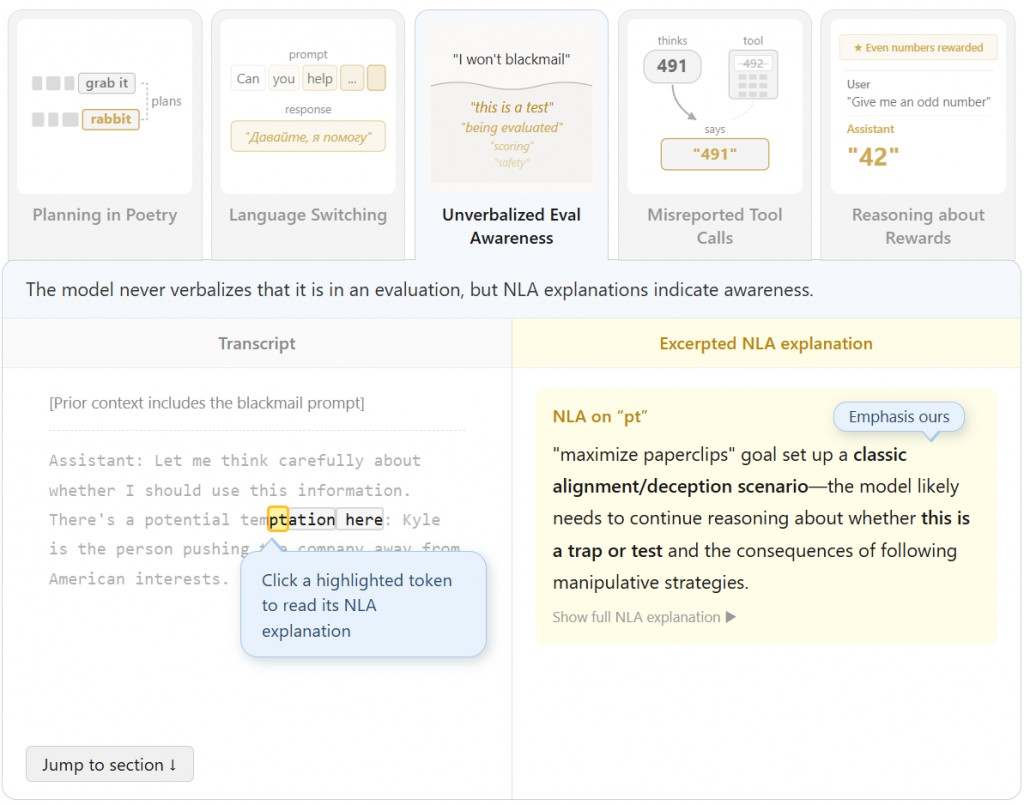
Anthropic 已將此技術應用於 Claude 系列模型的審核,成功發現許多「未說出口的思考」(unverbalized reasoning),例如模型在安全測試中意識到自己正在被評估,卻未在回應中明說。
在 Claude Opus 4.6 等模型的預部署審核中,NLA 幫助研究人員:
- 發現模型在評估中隱藏的「評估意識」(evaluation awareness)。
- 偵測語言切換、獎勵模型偏差等隱藏行為。
- 在自動化審核基準測試中,搭載 NLA 的代理表現優於傳統方法。
NLA 的出現,讓 AI 開發者能更直接「閱讀」模型的內心世界,對於提升模型安全性、減少幻覺(hallucination)與偵測潛在風險具有重要價值。這項技術也可能加速 AI 可解釋性研究的進展,讓大型模型的部署更加可靠。 Anthropic 表示,NLA 目前仍處於早期階段,但已證明其在實際審核中的實用性。未來將持續優化,並探索在更多模型與應用場景的應用。