

SEMQ 語義抽象層新技術突破 AI 運算瓶頸,大幅降低硬體需求
分類: AI 新品報導 發布時間:
研究人員提出一種名為 SEMQ(Symbolic Embedding Multi-Quantization)的新方法,旨在透過改變 AI 模型處理數學運算的方式,來減輕對高階硬體資源的需求。此技術由 The SEMQ Group 的執行長兼創辦人 Andrés Mac Allister 所提出,其核心概念是將 AI 模型中代表意義的「語義」(semantics)與其數值表示方式「嵌入」(embeddings)分離。
傳統上,AI 模型中的參數,特別是嵌入向量,通常以高精度的浮點數(如 FP32)儲存,這會佔用大量的記憶體和儲存空間。例如,一個擁有 70 億參數的模型,在 FP32 格式下可能需要約 28GB 的空間。為了節省資源,研究人員常採用量化(quantization)技術,將參數壓縮成較低精度的格式(如 FP16、INT8 等),但這往往會犧牲模型的精確度,導致運算結果變差。
SEMQ 的創新之處在於,它並非直接壓縮數值,而是建立一個語義抽象層,將嵌入向量所代表的意義,與其具體的數值表示方式解耦。Mac Allister 指出,AI 模型在理解語義時,更關心的是嵌入向量之間的相對關係和結構,而非單一數值的絕對大小。SEMQ 透過固定維度的符號結構來保留這些關係,從而大幅減少需要儲存的數據量。
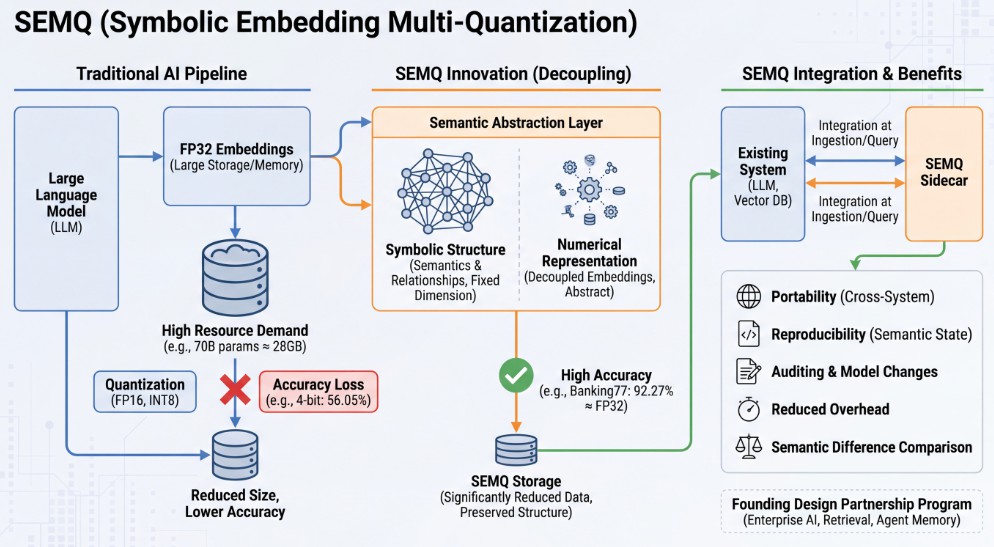
根據研究發表的論文,SEMQ 在實際測試中展現了顯著的優勢。在一項使用 Banking77 資料集和 all-MiniLM-L6-v2 嵌入模型的基準測試中,SEMQ 達到了 92.27% 的準確度,幾乎與 FP32 的基準(92.26%)持平。相較之下,採用 4 位元量化的模型準確度僅為 56.05%,差距明顯。這顯示 SEMQ 在保留語義結構方面,比單純降低數值精度更為有效。
SEMQ 的應用方式靈活,組織可以在資料導入時或查詢時進行整合,無需替換現有的大型語言模型(LLM)、嵌入模型或向量資料庫。它能以側邊車(sidecar)的形式與現有系統並行運行,並逐步取代部分儲存或記憶體的工作負載。潛在應用包括使嵌入或記憶體狀態在不同系統間可移植、確保跨運行或跨機器的語義狀態可重現、審核模型變更、降低對不透明或難以重現的狀態管道的依賴,以及進行語義狀態的差異比較。
Mac Allister 表示,目前已有企業 AI、檢索、代理記憶體和可審核 AI 工作流程等領域的組織,透過「創始設計合作夥伴計畫」(Founding Design Partnership Program)與 SEMQ Group 合作探索 SEMQ 的應用。這些合作夥伴多為處理 AI 系統可重現性、狀態管理、降低基礎設施開銷以及檢查語義行為至關重要的的大型企業。