

百度開源 Unlimited-OCR 工具,實現長文件「一鏡到底」解析
分類: AI 新品報導 發布時間:
百度近日在 GitHub 上正式開源 Unlimited-OCR 專案,宣稱將推動文件 OCR 技術進入「一鏡到底」(One-shot Long-horizon Parsing)的新時代。這款工具以 DeepSeek-OCR 為基礎,專注於一次性處理長文件、多頁 PDF 或複雜排版文件,適合企業文件自動化、學術論文解析與數位典藏等應用。
主要特色
- 長文件處理能力:支援單次輸入長達數萬 token 的文件解析,減少傳統 OCR 需要分頁處理的繁瑣步驟。
- 多格式支援:可直接處理單張圖片、多張圖片或完整 PDF 文件。
- 開源與易用:基於 Hugging Face Transformers 與 SGLang 框架,提供完整 Python 範例。
- 模型優勢:在複雜排版、表格、公式與手寫文字辨識上表現優異。
如何下載與安裝
clone專案:
git clone https://github.com/baidu/Unlimited-OCR.git
cd Unlimited-OCR 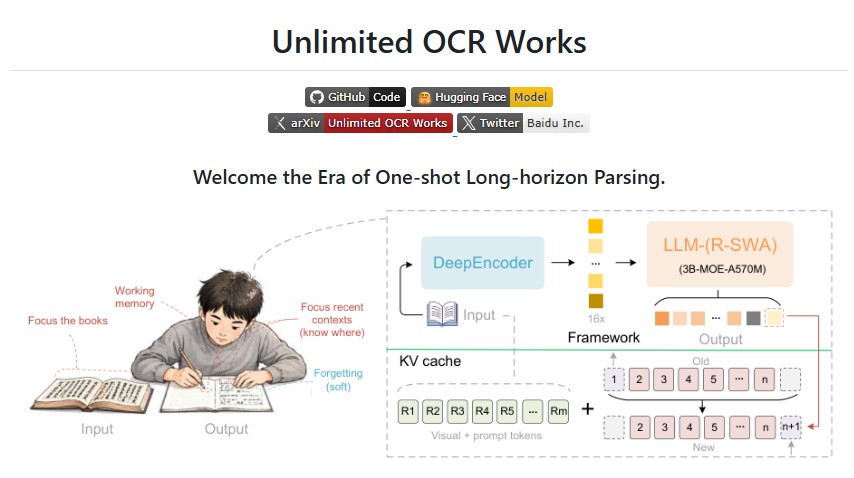
使用 Transformers(推薦 NVIDIA GPU):
需要 Python 3.12+ 與 CUDA 12.9 環境,安裝依賴套件:
pip install torch torchvision transformers Pillow matplotlib einops addict easydict pymupdf psutil 使用 SGLang(高效推論):
先安裝本地 wheel 檔案,再安裝相關依賴。
Python 串接範例
單張圖片處理
from transformers import AutoModel, AutoTokenizer
import torch
model_name = 'baidu/Unlimited-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
use_safetensors=True,
torch_dtype=torch.bfloat16
).eval().cuda()
model.infer(
tokenizer,
prompt='document parsing.',
image_file='your_image.jpg',
output_path='output_dir',
base_size=1024, image_size=640, crop_mode=True,
max_length=32768,
save_results=True
) 多頁 PDF 處理
import fitz # PyMuPDF
import tempfile, os
def pdf_to_images(pdf_path, dpi=300):
doc = fitz.open(pdf_path)
tmp_dir = tempfile.mkdtemp(prefix='pdf_ocr_')
mat = fitz.Matrix(dpi / 72, dpi / 72)
paths = []
for i, page in enumerate(doc):
out = os.path.join(tmp_dir, f'page_{i+1:04d}.png')
page.get_pixmap(matrix=mat).save(out)
paths.append(out)
doc.close()
return paths
# 使用 infer_multi 處理
model.infer_multi(
tokenizer,
prompt='Multi page parsing.',
image_files=pdf_to_images('your_doc.pdf', dpi=300),
output_path='output_dir',
image_size=1024,
max_length=32768,
save_results=True
) 使用注意事項
- 硬體需求:建議使用具備充足 VRAM 的 NVIDIA GPU(至少 24GB 以上較佳),否則處理長文件時可能出現記憶體不足。
- 模型大小:完整模型較大,下載與載入需較長時間,建議使用 ModelScope 或 Hugging Face 快取機制。
- 授權與隱私:專案採用 MIT 授權,但處理的文件若涉及敏感資料,需注意隱私保護與合規問題。
- 效能優化:長文件處理時可調整 max_length、ngram_window 等參數以平衡速度與準確度。
- 更新頻率:專案尚在早期階段,建議定期檢查 GitHub 以取得最新版本與修正。
參考來源:
GitHub 專案: https://github.com/baidu/Unlimited-OCR